The Transformer: Part 1
In 2017, engineers at Google invented the transformer and then did nothing with it.

Arguably the greatest paper of the past 10 years, "Attention is all you need" introduced the model architecture that became the standard for the entire field. The paper wasn't radical. Nerds at Google made some incremental changes on preexisting work, but whatever... At the time there was almost no indication that it a invention worthy of a million bucks.
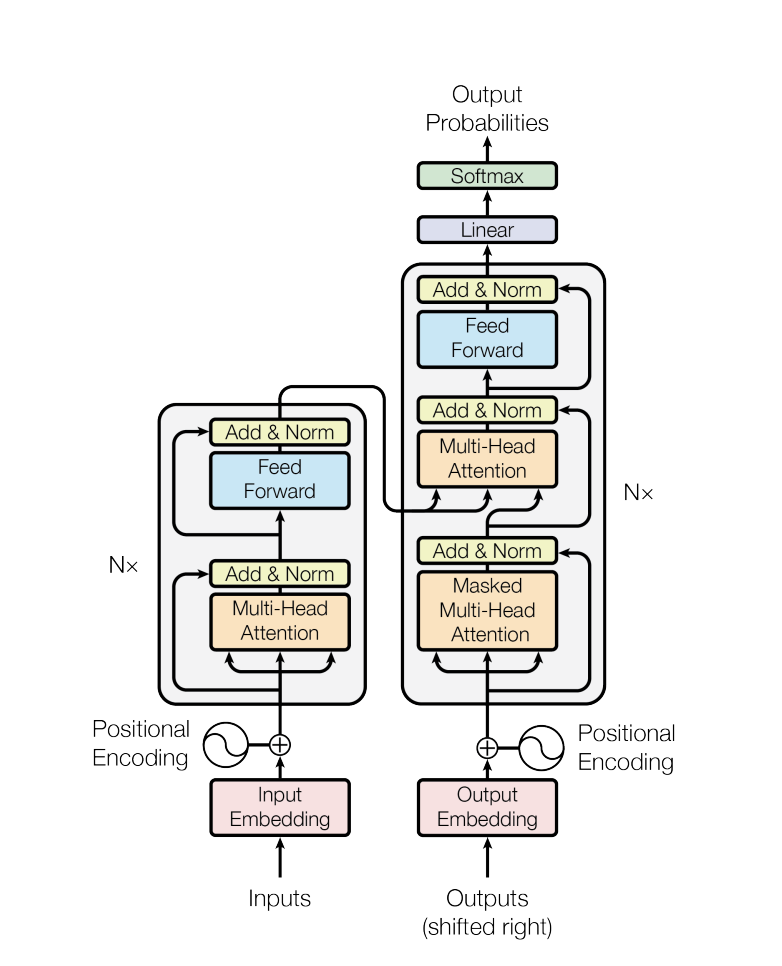
Above, lies the 'graph' of the network. Liken it to an assembly line of operations that are processed one after the other. At the bottom, the 'Input Embeddings' are a altered representation of one language, say English, and 'Output Embeddings' are similarly altered representation of the second language, say Spanish. Both of these are fed in the bottom, work their way through the 'nodes' of the graph, and out the top, arrive the result.
There are many details on what each node does, what arrows represent, etc. Below is the functional gist.
Lets say we have the following sentences:
Input: Sheriff, this is no time to panic.
Output: Alguacil, este no es momento para entrar en pánico.
As it's trained, a 'mask' is applied to the Spanish text (output embeddings). This 'look ahead mask' is progressively unrolled one *word* at a time. Applying the mask forces the model to predict *words* one at a time where BLANK represents the slot in which the model inserts its guess.
Attempt 1:
Input: Sheriff, this is no time to panic.
Output: BLANK
Attempt 2:
Input: Sheriff, this is no time to panic.
Output: Alguacil, BLANK
Attempt 3:
Input: Sheriff, this is no time to panic.
Output: Alguacil, este BLANK
...
*words aren't used directly. Instead, its sub letter combinations called tokens.*
They repeated this thousands of times, as per the standard (completable in a couple of nights), and BOOM. Researchers at Google had yet another AI toy.
How did the industry go from language translation to realistic human conversation in a couple of years?
Well they decided to make everything bigger. Make the dataset bigger. Make the models bigger. Train it for longer.
Instead of 4,500,000 English to German sentence pairs, it's (almost) everything anyone anywhere has ever written (basically the internet). GPT-4 was trained on a dataset ~100,000,000x the size of this paper's dataset.
Instead of 786,432 parameters, it's 1,760,000,000,000 parameters for GPT-4. (parameters is a measure of model size)
Instead of days, it's months of training. Thousands of computers. Millions in electricity bills.
This trend is not unique to OpenAI and friends. Since the transformer has caught on, average model size has increased 4 orders of magnitude from 2018 to 2022 . Below is a graph of model size with respect to time for the whole field. Source

The transformer's impact has been profound, sparking a paradigm shift in the field and paving the way for the development of powerful language models that continue to push the boundaries of what is possible with artificial intelligence. BUT! how do you have a conversation with a transformer? See part 2
Comments
Post a Comment